Техники машинного обучения для прогнозирования цен акций: функции индикаторов и анализ новостей
В случае применения методов машинного обучения для обработки торговых данных, чаще используют именно метод технического анализа — цель заключается в том, чтобы понять, может ли алгоритм точно определять паттерны поведения акции во времени. Тем не менее, машинное обучение может использоваться также для оценки и прогнозирования результатов деятельности компании для дальнейшего использования при фундаментальном анализе. В конечном итоге, наиболее эффективным методом автоматизированного предсказания цены акций и генерирования инвестиционных рекомендаций является гибридный подход, сочетающий в себе подходы фундаментального и технического анализа.
Гипотеза эффективного рынка
Гипотеза эффективного рынка (Efficient Market Hypothesis, EMH) предполагает, что вся существенная информация немедленно и в полной мере отражается на рыночной курсовой стоимости ценных бумаг. Существует три формы рыночной эффективности: слабая, средняя и сильная. Слабая форма подразумевает, что стоимость рыночного актива полностью отражает прошлую информацию, а сильная — что стоимость отражает всю информацию, как прошлую, так и публичную или внутреннюю.
Гипотеза случайного блуждания
Математическая модель случайного блуждания (Random Walk Hypothesis) предполагает, что изменения цены акций на каждом шаге не зависит от предыдущих и от времени. Таким образом невозможно выявить никакие паттерны поведения цены и использовать их.
Функции индикаторов
Для технического анализа рыночных цен используются различные атрибуты и индикаторы. К последним относятся, к примеру,:
- Скользящие средние (Moving Average, MA) — отображают средние n прошлых значений до текущего момента;
- Экспоненциальная скользящая средняя (Exponential Moving Average, EMA) — придает больше веса наиболее недавным значениям, но не отбрасывает старые значения полностью;
- Моментум или скорость изменения (Rate of Change, RoC) — один из самых простых технических индикаторов, рассчитываемый как отношение или разница между текущей ценой и ценой n периодов назад.
- Индекс относительной силы (Relative Strength Index, RSI) — определяет силу тренда и вероятность его смены в течение определенного времени (обычно, 9-14 дней).
Для описываемого проекта в качестве главного индикатора был выбран EMA — он позволяет обрабатывать практически неограниченный объём исторических данных, что очень важно для анализа с помощью временных рядов. Однако стоит заметить, что использование других индикаторов может приносить и большую точность прогнозов анализируемых акций.
EMA (t) = EMA (t-1) + alpha * (Price (t) — EMA (t-1))
где, alpha = 2/ (N+1), таким образом, for N=9, alpha = 0.20
В теории, проблема предсказания цены акции может быть рассмотрена, как оценка функции F во времени T на основе предыдущих значений F во время t-1,t-2 … t-n, присваивая соответствующую весовую фукнцию w на в каждый момент F:
F (t) = w1*F (t-1) + w2*F (t-2) + … + w*F (t-n)
График ниже показывает, как EMA моделирует текущую цену акций:
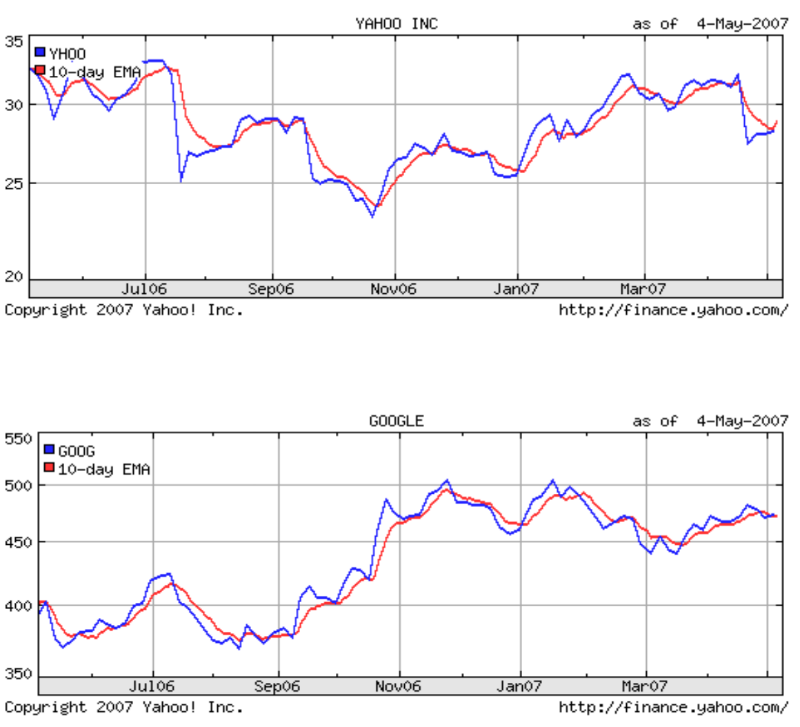
Среда обучения
В ходе проекта были использованы среды для дата-майнинга Weka и YALE. Конфигурация выглядела таким образом:

Шаг выбора атрибутов для некоторых методов машинного обучения был пропущен, поскольку общее их количество составляло меньше 10.
Предобработка исторических данных
Для эксперимента с сайта Yahoo Finance были загружены исторические данные по ценам акций компаний Google Inc. (тикер GOOG) и Yahoo Inc. (YHOO). Набор данных имел следующие атрибуты: Date Open High Low Close Volume Adj. Close.
Индикатор EMA предполагает, что цена акции в предыдущий день торгов будет оказывать на текущую цену наибольшее значение. Таким образом, чем ближе временная точка находится к текущему моменту, тем большее значение она оказывает на цену текущего дня. В ходе временного анализа исследователь брал Дату в качестве оси X — каждая дата представляла собой целое значение. К имеющимся атрибутам был добвлен еще один — Indicator, в данном конкретном случае EMA.
Техники машинного обучения
В данной секции исследования представлены результаты применения различных алгоритмов машинного обучения.
Алгоритм Decision Stump
Применения простого алгоритма для предсказания EMA позволило добиться следующих результатов:
- Коэффициент корреляции 0.8597
- Средняя абсолютная ошибка 46.665
- Корень среднеквадратичной ошибки 57.8192
- Относительная абсолютная ошибка 46.8704 %
- Корень среднеквадратичной относительной ошибки 50.9763 %
- Общее число периодов 681
Линейная регрессия
Применение простой линейной регрессии (используются только численные атрибуты) для предсказания EMA дали следующие результаты:
- Коэффициент корреляции 0.9591
- Средняя абсолютная ошибка 12.9115
- Корень среднеквадратичной ошибки 32.0499
- Относительная абсолютная ошибка 12.9684 %
- Корень среднеквадратичной относительной ошибки 28.2568 %
- Общее число периодов 681
Метод опорных векторов
Использование метода опорных векторов (C-Class) с прмиенение радиальной базисной функции ядра с параметром настройки C в диапазоне от 512 до 65536, позволило получить следующую точность прогнозирования движения цены:
Корень среднеквадратичной ошибки: 0.486 ± 0.012
Точность: 60.20 ± 0.49%
Бустинг
После использования алгоритма C-SVC к набору данных был применен алгоритм бустинга AdaBoostM1 — это позволило добиться серьезного улучшения точности.
Корень среднеквадратичной ошибки: 0.467 ± 0.008
Точность: 64.32% ± 3.99%
Из выходных данных YALE была извлечена следующая матрица неточностей:

Предсказание цен акций на основе текстового анализа финансовых новостей
В настоящее время большой объём ценных данных, которые могут повлиять на ситуацию на рынке, доступен в сети (о подобном влиянии мы писали в своей статье ). Большая часть такой информации содержится в финансовых новостях, отчетах компаний и рекомендациях экспертов (источником таких рекомендаций, к примеру, могут служить блог инсайдеров и аналитиков). Большая часть этих данных представлена в текстовом формате, что затрудняет их использование. Таким образом, новая проблема заключается в необходимости анализа текстовых документов одновременно с выполнением анализа временных рядов.
Исследователь использовал метод, который подразумевает определение степени влияния новостей на конкретную акцию: оно может быть позитивным (Positive), негативным (Negative) или нейтральным (Neutral).
Считается, что новость имеет положительное влияние (или негативное), если цена акции серьезно растет (или падает) в период сразу после ее публикации. Если цена акции серьезным образом не изменяется после публикации новости, то ее влияние считается нейтральным.
Другой использованный метод подразумевает определение паттернов в новостных статьях, которые напрямую соовтетствуют росту или снижению цены акций. Он работает следующим образом:
Специальный поисковый робот проходит по новостным статьям и индексирует их для конкретного портфолио акций. Среда обучения запрашивает новости за период T минут с момента индексации. Эта среда состоит из несколько модулей обучения, которые ищут нужную информацию в тексте новостной заметки или материалах из блогов экспертов (например, «цена нефти будет снижаться»). В словарь для анализа входят слова и фразы, влияющие на условия положительного (Positive Prediction Terms) или негативного движения (Negative Prediction). Каждый раз, когда фраза из набора Positive Prediction Terms появляется в тексте статьи, ей присваивается положительная оценка (Positive Vote).
На диаграмме ниже представлена архитектура такой системы:

Как нетрудно заметить, данный метод позволяет делать лишь довольно грубые предположения. Чтобы повысить их точность необходимо добавить статьям больше весов — например, на основе ранжирования источников информации для публикации. Кроме того, следует учитывать форматы заголовков текстов, содержащие фразы из наборов Positive или Negative Prediction Terms.
Использование в качестве веса новости авторитетности экспертов
Исследователь также описывает использование для дополнительного взвешивания текстовых материалов оценку авторитетности экспертов, высказывающих ту или иную точку зрения. К примеру, для акций Google он подобрал список аналитиков, которые долгое время пишут об этой компании, и звездочками отметил степень качества их прогнозов:

На вход системы подаются мнения экспертов рынка акций (просто их мнение, которое необязательно оказывается верным), а затем на основе их прогнозов раз за разом делаются предсказания возможного движения цены. На каждой итерации вес эксперта, чье предсказание оказалось верно, повышается, а у тех, кто ошибся — наоборот снижается. Еще одна разновидность метода предполагает полное удаление из списка тех экспертов, которые ошиблись, однако он является не самым эффективным — все-таки ошибаются даже самые лучшие и уважаемые финансовые аналитики.
Алгоритм взвешивания экспертов может быть описан следующим образом:
Дано: вектор E = < e1, e2,….eN>финансовых экспертов и их прогнозов.
Присвоить вес W(e(i)) = 1 для каждого эксперта e(i).
Для раунда t in 1…T
Сделать предсказание на основе алгоритма взвешенного большинства.Для экспертов, которые сделали верный прогноз W(e(i))(t) = 2*W(e(i))(t-1)
Для экспертов, которые сделали неверный прогноз W(e(i))(t) = ½ * W(e(i))(t-1)
Сохранить рейтинг эксперта (Expert Rating) для последующего взвешивания.
Такую технику взвешивания на основе экспертных мнений можно рассматривать в качестве гибридного подхода, комбинирующего в себе фундаментальный и технический анализ — эксперты делают прогнозы на основе фундаментального анализа, а алгоритм впоследствии использует их для генерирования собственных прогнозов с помощью методов технического анализа.
Заключение
Из всех использованных алгоритмов только комбинация метода опорных вектора и алгоритма бустинга позволили добиться сколько-нибудь удовлетворительных результатов точности прогноза.
Другим перспективным методом анализа является взвешивание экспертов. Однако в настоящий момент эффективность методов лингвистического анализа для генерирования прогнозов движения цен акций является предметом дальнейшего изучения и каких-то определенных выводов о его применимости на практике сделать нельзя.
Читайте также
Этот пост основан на статье, носящей название «Моделирование динамики высокочастотного портфеля лимитных ордеров методом опорных векторов». Грубо говоря, я ступенька за…
Начнём с того, что объявить в lua-скрипте функцию достаточно просто: function somefunc(key, value) — something end Однако при запуска такого…
imap_sort — одна из нескольких функций, с помощью которой можно получить список писем в почтовом ящике. Один из её параметров…
5 мощных проектов по машинному обучению для начинающих
Сайт proglib.io представил перевод статьи, посвященной машинному обучению.

В этой статье мы расскажем о пяти идеях, используя которые вы сможете реализовать действительно хорошие проекты по машинному обучению.
Как вы знаете, количество изученного теоретического материала не может заменить практику. Теоретические уроки и книги могут внушить вам ложное представление о том, что вы достаточно изучили материал и хорошо разбираетесь в теме. Однако как только вы попробуете применить полученные знания, вы поймёте, что материал на деле сложнее, чем в теории.
Эти проекты помогут вам усовершенствовать навыки по машинному обучению и изучить новые темы. К тому же, выполненные проекты прекрасно дополнят ваше портфолио, что будет плюсом при трудоустройстве.
Поработайте с финансовыми рынками
Финансовый рынок — отличная вещь для любого Data Scientist, даже для того, кто далек от финансовой сферы.
Во-первых, у вас есть огромный выбор: вы можете работать с ценами, фундаментальными данными, глобальными макроэкономическими показателями, индексами волатильности и т. д.
Во-вторых, данные могут быть очень подробными. Вы можете с лёгкостью получить данные любой компании по дню (или даже минуте). Это поможет вам творчески обдумывать торговые стратегии.
Наконец, финансовые рынки имеют короткие циклы отклика, поэтому вы сможете быстро перестроить прогноз под новые данные.
Некоторые идеи для проекта:
- Количественное инвестирование — спрогнозируйте движение цены в течение 6 месяцев, основываясь на фундаментальных показателях в ежеквартальных отчётах компаний.
- Прогноз — создайте модели временных рядов или рекуррентных нейронных сетей на разности между подразумеваемой и фактической волатильностью.
- Статистический арбитраж — найдите схожие рынки по движениям цен и другим факторам и ищите периоды, когда цены начинают расходиться.
Очевидно, что написание подобных проектов лишь для практики в машинном обучении — простая вещь. Однако монетизация, извлечение материальной выгоды из подобных проектов — максимально сложная практика. Ничего из вышесказанного не является финансовым советом, и мы крайне не рекомендуем торговать реальной валютой, если вы не разбираетесь в рынках.
- видео по машинному обучению, применяемому для инвестирования.
Источники данных:
- , который предоставляет бесплатные (и премиум) финансовые и экономические данные. Например, вы можете скачать цены на конец дня для более 3000 американских компаний или экономические данные из Федерального резерва.
- Количественное финансовое сообщество, которое предлагает бесплатную платформу для разработки алгоритма торговли, включает в себя наборы данных. 5000+ американских компаний за последний 5 лет.
Создайте нейросеть, которая распознаёт текст, написанный от руки
Нейронные сети и Deep Learning — два главных прорыва в развитии современного искусственного интеллекта. Они привели к большим достижениям в области распознавания объектов (прочитайте нашу статью про распознавание объектов на Python), генерации текстов и даже в области беспилотных автомобилей.
Чтобы больше углубиться в эту тему, вам стоит начать с чего-то попроще, не с изображений.
MNIST Handwritten Digit Classification Challenge — стандартная точка входа. С изображениями работать гораздо сложнее, чем с реляционными моделями данных. MNIST данные дружелюбны по отношению к новичкам и имеют небольшие размеры, так что с лёгкостью поместятся на одном компьютере.
Для начала мы рекомендуем начать с первой главы обучения ниже. Там вы научитесь создавать нейросеть на Python с нуля, которая будет распознавать письменный текст с большой точностью.
- по нейросетям и Deep Learning.
Источник данных:
Исследуйте Enron
Скандал Enron был самым большим корпоративным кризисом в истории.
В 2000 Enron была одной из самых больших энергетических компаний в Америке. Затем, когда компанию уличили в мошеннических махинациях, она обанкротилась в течение года.
К счастью для нас, есть данные e-mail переписок бывших сотрудников Enron. Это 500 тысяч электронных писем между 150 бывшими сотрудниками, в основном, старшими руководителями. Это также единственная крупнейшая публичная база данных электронных писем, что делает её ещё более ценной.
Фактически, Data Scientist используют этот набор данных уже много лет для проектов по машинному обучению.
Проекты по машинному обучению, которые вы можете попробовать реализовать:
- Анализ текста сообщений и их классификация по степени важности, целям и проч.
- Социальный анализ. Создайте сеть сотрудников и посредством анализа сообщений найдите ключевых влиятельных лиц.
- Обнаружение аномалий. Проанализируйте входящие и отправленные сообщения по часам и попытайтесь обнаружить “ненормальное” поведение, которое привело к общественному конфликту.
Источники данных:
Улучшите заботу о здоровье
Ещё одна отрасль, которая активно развивается благодаря проектам по машинному обучению — это здравоохранение и забота о здоровье.
Во многих странах для того, чтобы стать доктором, необходимо потратить много лет на обучение. Порог вхождения в эту сферу довольно велик, а процесс становления врачом очень сложен.
В результате в последнее время предпринимаются значительные усилия для облегчения рабочей нагрузки врачей и повышения общей эффективности системы здравоохранения с помощью машинного обучения.
Возможные проекты:
- Профилактическая помощь — прогнозирование заболеваний как на индивидуальном, так и на общем уровне.
- Диагностическая помощь — автоматическая классификация изображений, например, сканы, x-ray и т. п.
- Страхование — определение страховых взносов на основе общедоступных факторов риска.
Гайды:
Источники данных:
- , связанных со здравоохранением
- Ещё один сборник данных, предоставленный правительством США — статистика здоровья и населения, предоставленная Всемирным банком.
Анализируйте социальные медиа
Социальные медиа уже практически стали синонимом “big data” из-за огромного количества контента, создаваемого пользователями.
Добыча этих данных — беспрецедентный способ сохранить руку на пульсе общественного мнения, настроения и трендов. Facebook, Twitter, YouTube, WeChat, WhatsApp, Reddit… Список можно продолжать и продолжать.
Кроме того, каждое последующее поколение тратит ещё больше времени на соцсети, чем предыдущее. Это значит, что данные в социальных сетях станут ещё более актуальными для маркетинга, брендов и бизнеса в целом.
Несмотря на то, что существует множество популярных социальных сетей, Twitter является классической точкой входа в практику машинного обучения.
С данными Twitter вы получаете интересное сочетание данных (содержимое твитов) и метаданных (местоположение, хештеги, пользователи, повторные твиты и т. д.), которые открывают вам почти бесконечное количество путей для анализа.
Источник https://evilinside.ru/texniki-mashinnogo-obucheniya-dlya-prognozirovaniya-cen-akcij-funkcii-indikatorov-i-analiz-novostej/
Источник https://techrocks.ru/2018/02/07/machine-learning-projects/
Источник